一般在设计通知中心时,都会在入口处显示一个未读消息数,这样不仅可以醒目地告知用户有未读消息,还能让用户更容易从众多小图标中区分出通知中心的入口。比如 ucloud 控制台的顶栏:
我们网站的通知中心也一样,在入口同样加上了未读消息数的显示。
上线后平稳运行,以为可以就这样一直美下去。程序只要有人用,总会有出 bug 的那一天,最近高峰期经常会出现来自通知表的慢查询语句,仔细一查,原来就是统计未读消息数的语句,而且都是来自几个大用户。我们通知里分了多个组,每个组都有自己的一个未读数,sql 语句差不多是下面这样:
SELECT groupID, count(0) unreadCount FROM notification WHERE userID=xxx AND hasRead=0 GROUP BY groupID;
notification 表中已建立未读索引 unreads: userID + hasRead + groupID 的组合键。
由于我们网站大多是批量异步操作,即使做了消息合并,一天产生几十上百条通知也很正常,而且有的用户就是不喜欢标记通知为已读,这样日积月累,有的用户未读数已经上十万了。假设总记录行有 20 万,如果未读数为 50,建立一个未读的索引,效率会非常显著;但是未读数为 15 万,这时索引的意义也不大了。所以这个性能问题直到现在才暴露出来。
当未读数比较小时:
结果集:
groupID | unreadCount
0 | 23
4 | 16
Explain:
id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra
1 | SIMPLE | notification | ref | unreads | unreads | 5 | const,const | 39 | Using where; Using index
耗时:0.4ms(测试数据)
当未读数比较大时:
结果集:
groupID | unreadCount
0 | 23
1 | 103234
3 | 3032
4 | 16
Explain:
id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra
1 | SIMPLE | notification | ref | unreads | unreads | 4 | const | 69886 | Using where; Using index
耗时:38.9ms(测试数据)
由上可以看出,未读的记录行数直接影响该语句的性能。
问题出现总归要解决的,如何解决呢?最直接的办法就是看看其他产品是怎么做的。LG 同学提出,可以优化成像 QQ 未读消息数那样显示 99+ 呀。QQ 上有几个群,每天都有人在里面吹水斗表情,消息一会不看就 99+ 了。当初以为这样只是为了排版美观,或者避免特别大的数字给用户造成很大的心理负担,再者也不会有人关心未读的消息是 101 还是 102,所以索性显示 99+。即告诉用户有很多未读消息,又不会因显示一个特别大的数字吓到用户,这样一举两得。但这样似乎只是对用户更友好,对性能然并卵。这时他再次提出可以把 sql 语句拆开来写,一开始我是拒绝的,按照过往经验,多条语句查出结果合并肯定没有单条语句 GROUP BY 来的快。有时经验也会害死人,于是 LG 给出了下面的语句:
SELECT 0 AS groupID, count(1) AS unreadCount FROM (SELECT 1 FROM notification WHERE userID=xxx AND hasRead='0' AND groupID = 0 LIMIT 100) AS a
UNION
SELECT 1 AS groupID, count(1) AS unreadCount FROM (SELECT 1 FROM notification WHERE userID=xxx AND hasRead='0' AND groupID = 1 LIMIT 100) AS a
UNION
SELECT 2 AS groupID, count(1) AS unreadCount FROM (SELECT 1 FROM notification WHERE userID=xxx AND hasRead='0' AND groupID = 2 LIMIT 100) AS a
UNION
SELECT 3 AS groupID, count(1) AS unreadCount FROM (SELECT 1 FROM notification WHERE userID=xxx AND hasRead='0' AND groupID = 3 LIMIT 100) AS a
UNION
SELECT 4 AS groupID, count(1) AS unreadCount FROM (SELECT 1 FROM notification WHERE userID=xxx AND hasRead='0' AND groupID = 4 LIMIT 100) AS a
这条语句精妙就精妙在 LIMIT 100,使用未读索引并把结果集限定在 100 行以内,这个速度是非常快的。
优化后的时间:
结果集:
groupID | unreadCount
0 | 23
1 | 100
2 | 0
3 | 100
4 | 16
Explain:
id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra
1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 23 | NULL
2 | DERIVED | notification | ref | unreads | unreads | 6 | const,const,const | 23 | Using index
3 | UNION | <derived4> | ALL | NULL | NULL | NULL | NULL | 100 | NULL
4 | DERIVED | notification | ref | unreads | unreads | 6 | const,const,const | 73020 | Using index
5 | UNION | <derived6> | ALL | NULL | NULL | NULL | NULL | 2 | NULL
6 | DERIVED | notification | ref | unreads | unreads | 6 | const,const,const | 1 | Using index
7 | UNION | <derived8> | ALL | NULL | NULL | NULL | NULL | 100 | NULL
8 | DERIVED | notification | ref | unreads | unreads | 6 | const,const,const | 3208 | Using index
9 | UNION | <derived10> | ALL | NULL | NULL | NULL | NULL | 16 | NULL
10 | DERIVED | notification | ref | unreads | unreads | 6 | const,const,const | 16 | Using index
NULL | UNION RESULT | <union1,3,5,7,9> | ALL | NULL | NULL | NULL | NULL | NULL | Using temporary
耗时:0.7ms(测试数据)
性能提升了几十倍,堵在胸口的这坨翔终于通了。这条语句的性能会因分组的数量所影响,但分组的数量是有限而且比较固定的,所以这个威胁不成立。
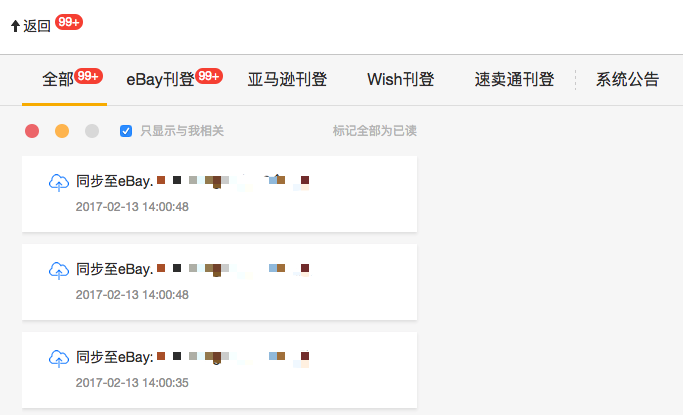
其实到这还没结束,还要结合前台,当 unreadCount 大于 99 时,就要显示 99+,优化后我们的通知中心未读提醒成了这样:
总结
优化不能单靠技术手段,有时产品上做下折中,优化的方法会简单很多。如果这次仅凭技术手段来优化,可能要引入缓存,或者冗余一个未读数,每次更新维护这个数字,这可能需要 2 ~ 3 天的工作量,而且还容易出 bug;而使用 99+ 的做法只花了不到 2 小时。另外也不能一直相信经验,经验有时也会犯错,而且会固化思维。